Strategies for deploying Machine Learning Inferences models using Lambda


There is more than one way to deploy a machine learning inference model using Lambda. Lambda is serverless and the Pay as you go option helps to address burst workload with no overhead of running or managing the infrastructure. Depending on the kind of workload and the use case, one of these options can be used.
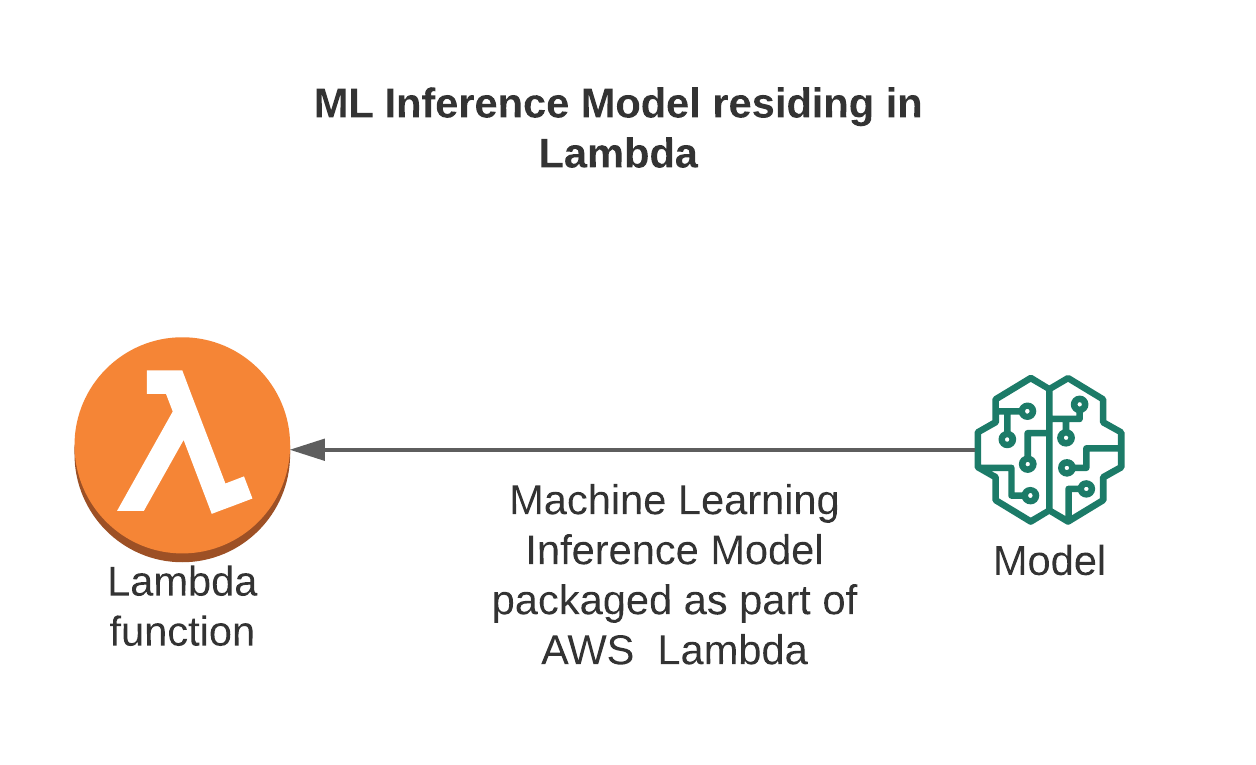
1.Inference Model packaged along with Lambda
Small models that can be packaged for small inference use cases. Tensor Flow Lite and few other models can be used here.
When to use
Prototyping, small models used in mobile apps or devices that have constraints with resources
Pros
Simple and easy to use
Cons
Models are usually large and cannot be packaged as part of Lambda using this approach. Continuous updates to the model mean re-deployment of lambda. There is no de-coupling of Lambda and Model
Reference
https://segments.ai/blog/pytorch-on-lambda
2.Inference Model packaged as Lambda layers
Here the Inference model is packaged as part of Lambda layers.

When to use
Model re-usability across different use cases.
Pros
- Simple and easy to use
- Lambda and Model are separately packaged even though the change in the model means redeployment of lambda layers and in turn Lambda itself
- Changes to the model can be updated in the layers alone and all Lambdas that are referencing the layers are automatically updated with the new updated model
Cons
- Models are usually large and cannot be packaged as part of Lambda
- Continuous updates to the model mean redeployment of lambda. There is no decoupling of Lambda and Model
- Lambda has a limitation of only 5 layers. This could be challenging.
Reference:
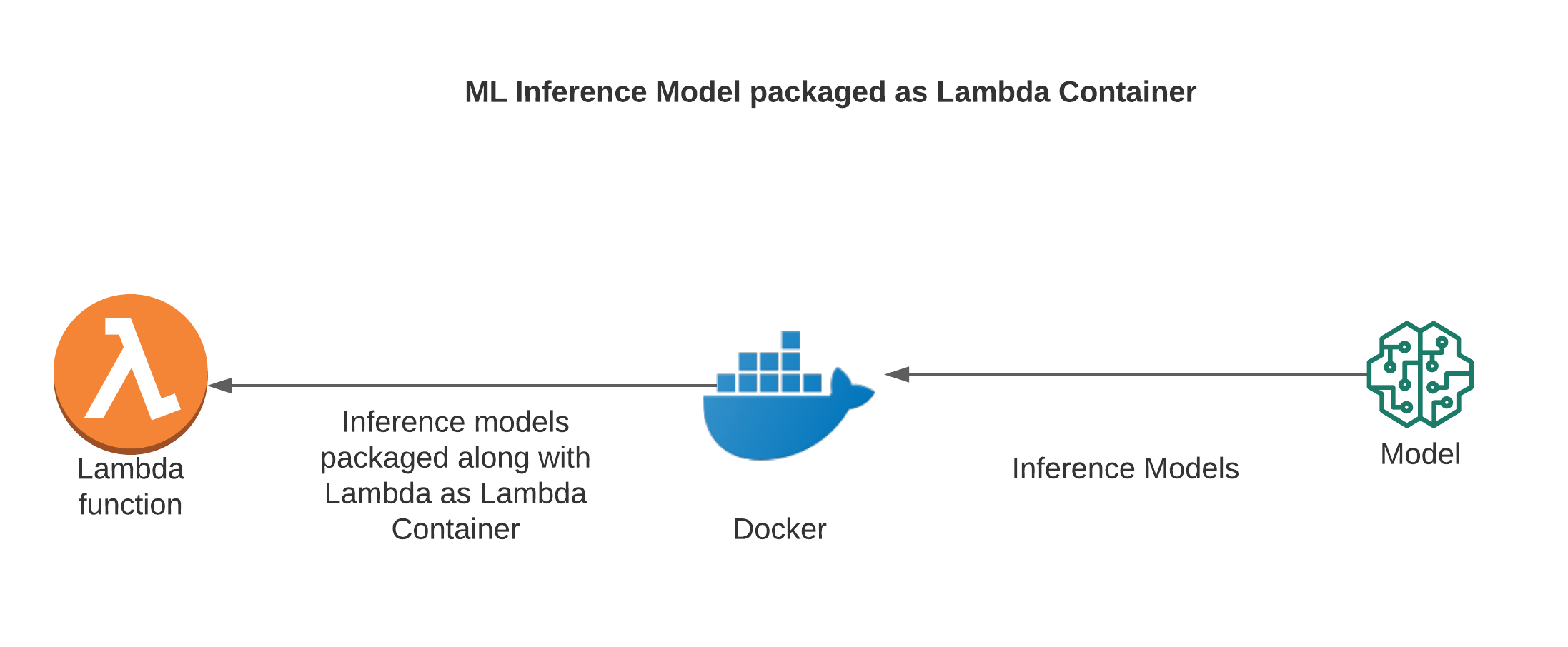
3.Lambda and Inference Model packages as Lambda Containers
This is the model that is recently available. Lambda and Model Inference can be packaged as a single container, pushed to ECR and then Lambda can use a container repository URI to load the packages
When to use
Pros
1.Fits the usual Lambda and serverless pattern
Cons
- Packaging allowed is up to a size of 10 GB. Inference Models that are larger than this size cannot use this approach.
Reference:
4.Inference Model loaded from S3 to Lambda
Here the Inference model is available in S3, and Lambda downloads the model for execution

When to use
Pros
- Simple and easy to use
- Lambda and Model are decoupled. Inference Models can be continuously updated with no need for a separate lambda deployment.
Cons
- Models are usually large and loading the complete model into Lambda for processing may take a really long time.
- Larger models cannot be loaded into Lambda
Reference
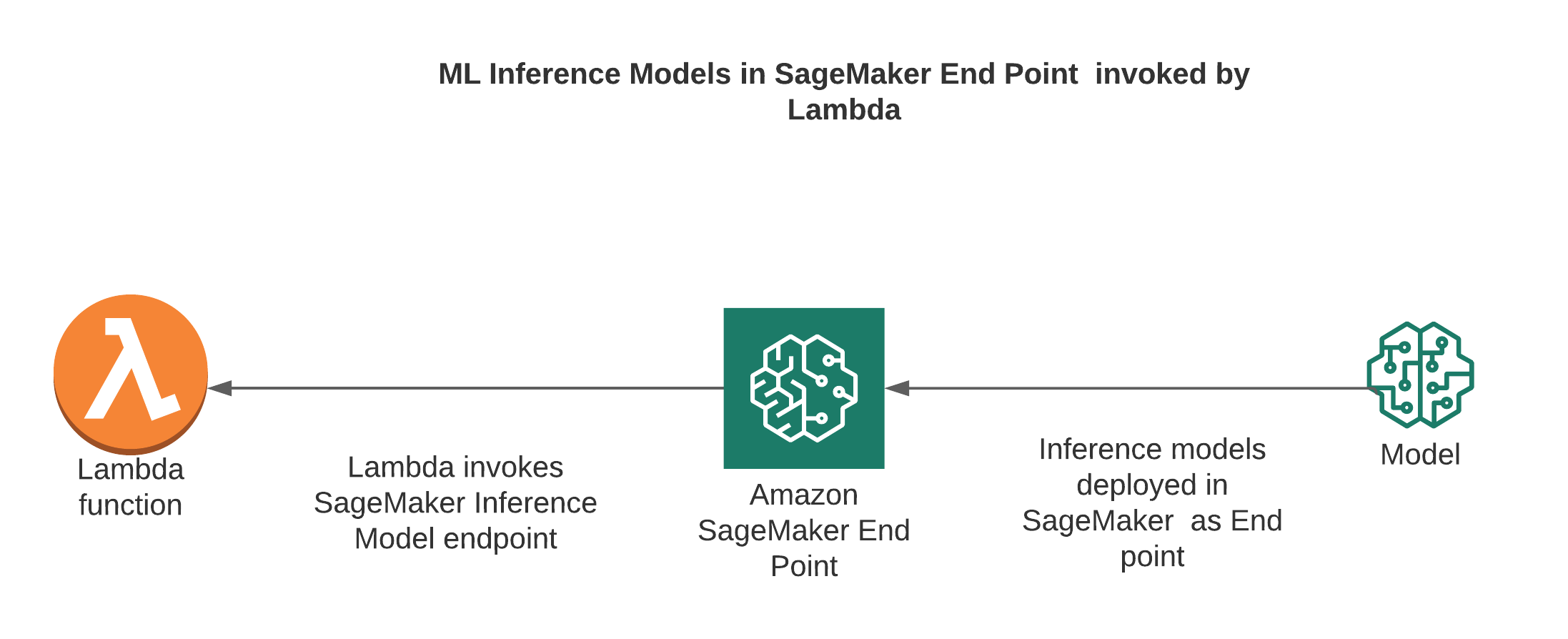
5.Lambda invoking Inference Model Endpoint available Sage Maker
Sagemaker is used for Machine Learning. It provides both training and inference model endpoints. Lambda can call the inference model endpoint available in Sage Maker. Calling an Inference model in SageMaker is just another API invocation and SageMaker by itself has no connection to Lambda whatsoever. This is yet another pattern followed in case pre-processing or post-processing logics are required based on the inference model response
When to use
If Sagemaker is already available for Model training, the inference is an additional step. It is always better to leverage the SageMaker Model Inference endpoint.
Pros
- Simple and easy to use
- Lambda and Model are decoupled. Inference Models can be continuously updated with no need for separate lambda deployment.
Cons
- Not part of typical Lambda use case
- Scaling and other challenges associated with the SageMaker Inference endpoint need to be addressed.
- SageMaker inference endpoints may not be serverless.
Reference
6.Lambda invoking Inference Model available in EFS
This is one of the newest approaches available. EFS can be used to both train and deploy models. EFS can also be mounted on the Lambda as an extension. This ensures that Model training and deployment into production can happen with no impact on Lambda deployment. Also, the cold start issue typically associated with loading a large model from S3 or other packages restriction can be avoided.

When to use
Pros
- Lambda and Model are decoupled. Inference Models can be continuously updated with no need for separate lambda deployment.
- EFS can scale really well.
- No cold start issues as the model downloading is not required here.
Cons
- Setup is slightly complex with the setting up of EFS and endpoints.
- EFS is not serverless. Need to pay for the services of EFS irrespective of its usage
Reference
https://medium.com/faun/setup-serverless-ml-inference-with-aws-lambda-efs-738546fa2e03
https://thenewstack.io/tutorial-host-a-serverless-ml-inference-api-with-aws-lambda-and-amazon-efs/
Summarizing all the major approaches in the form of matrix
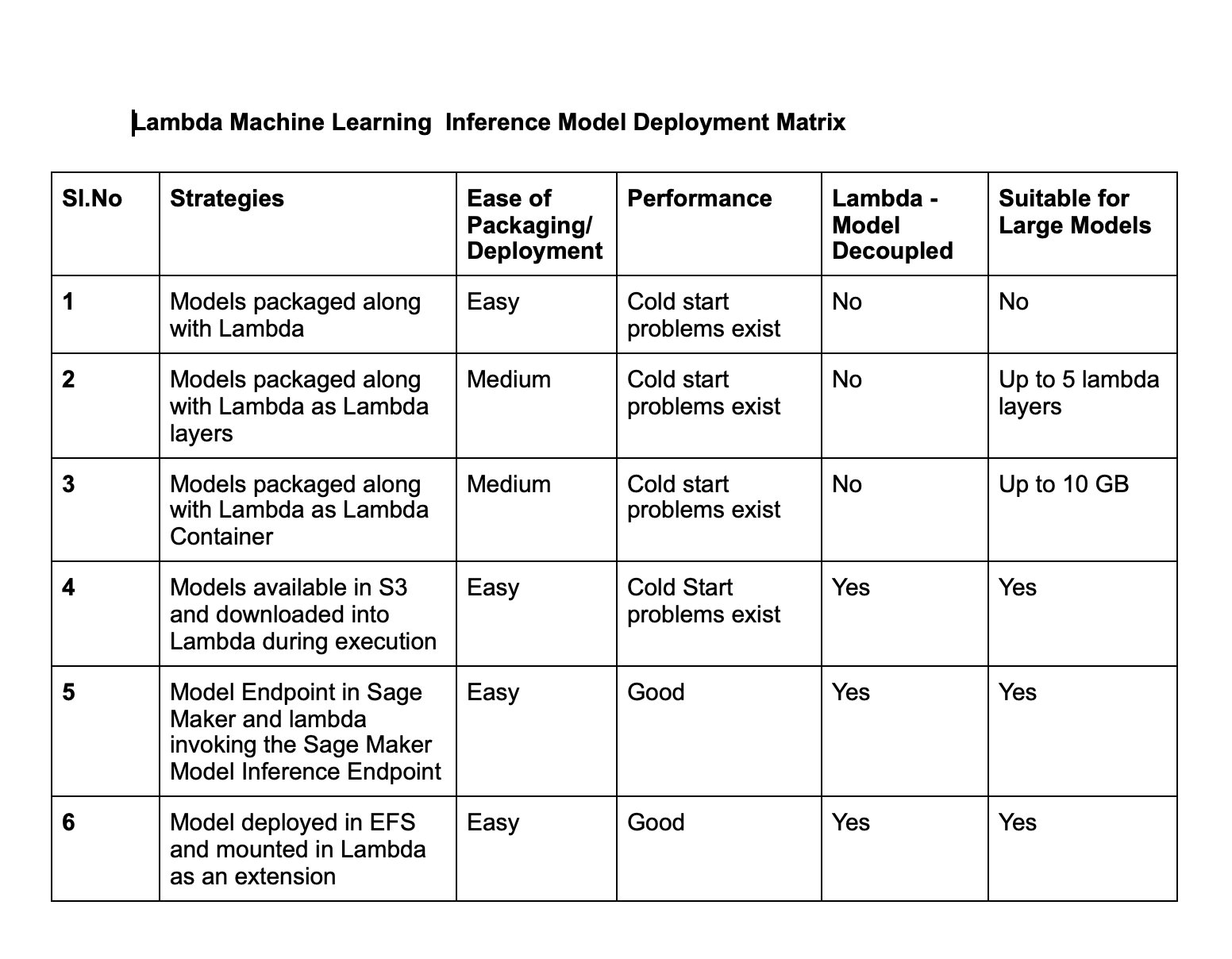
These are some of the various approaches that can be used to run Model Inference use cases in Lambda. Should you feel this writeup has missed any approaches please write to the author.